MySQl 专栏继续更新 不说不流畅难明的东西 尽量输出简略了解 和 运用的SQL技巧 和 初中级开发不是很常用的但很有用的知识
欢迎检查SQL 专栏 查漏补缺 指导一二

本文正在参加「技能专题19期 闲谈数据库技能」活动
前语
经过思路解析 剖析SQL书写 拆分逻辑 简略易懂 跟着学习 等系列更新完 SQL编写才能 和 SQL思维都会有提升 欢迎重视专栏 假如有更简略的接替办法 能够发在评论区会弥补完善
简略
难度:

创立表
DROP TABLE IF EXISTS `world`;
CREATE TABLE `world` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`continent` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`area` int(11) NULL DEFAULT NULL,
`population` int(11) NULL DEFAULT NULL,
`gbp` bigint(100) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of world
-- ----------------------------
INSERT INTO `world` VALUES (1, 'Afghanistan ', 'Asia ', 652230, 25500100, 20343000000);
INSERT INTO `world` VALUES (2, 'Albania ', 'Europe ', 28748, 2831741, 12960000000);
INSERT INTO `world` VALUES (3, 'Algeria ', 'Africa ', 2381741, 37100000, 188681000000);
INSERT INTO `world` VALUES (4, 'Andorra ', 'Europe ', 468, 78115, 3712000000);
INSERT INTO `world` VALUES (5, 'Angola Africa ', 'Africa ', 1246700, 20609294, 100990000000);
SET FOREIGN_KEY_CHECKS = 1
问题
假如一个国家满意下述两个条件之一,则认为该国是 大国 :
- 面积至少为 300 万平方公里(即,
3000000 km2),或许 - 人口至少为 2500 万(即
25000000)
编写一个 SQL 查询以报告 大国 的国家称号、人口和面积。
按 任意次序 返回结果表。
查询结果格局如下例所示。

剖析
这个真的是十分简略 算是最根底的SQL句子 面积 至少(>=) 300万平方 或许(or) 人口至少(>=) 2500万 字面意思翻译一下便是SQL 句子
SELECT name , population ,area from world where area >= 3000000 or population >=25000000

上面这个是最简略一种方式 可是咱们知道 Or 是不走索引 所以咱们应该还是有其余的解法
咱们衔接除了and or 还有 UNION 其实or便是将两个条件的数据集进行结合 UNION 也是这种意思 可是缺点是 需要进行两次查询 要说哪种更好 感觉我差异不大 便是一种写法上的思想
SELECT name, population, area
FROM world
WHERE area >= 3000000
UNION
SELECT name, population, area FROM world WHERE population >= 25000000

简略的解说一下OR 和 UNION的一些东西
对于单列来说,用or是没有任何问题的,可是or涉及到多个列的时候,每次select只能选取一个index,假如挑选了area,population就需要进行table-scan,即悉数扫描一遍,可是运用union就能够处理这个问题,分别运用area和population上面的index进行查询。 可是这儿还会有一个问题便是,UNION会对结果进行排序去重,可能会降低一些performance(这有可能是办法一比办法二快的原因),所以最佳的挑选应该是两种办法都进行尝试比较
简略一点的话能够直接运用OR 这个问题比较简略 假如思路错了就真的要好好训练一下了
中等
难度:
创立表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`c_id` int(11) NOT NULL AUTO_INCREMENT,
`c_name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`t_id` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`c_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course` VALUES (1, '语文', 2);
INSERT INTO `course` VALUES (2, '数学', 1);
INSERT INTO `course` VALUES (3, '英语', 3);
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`s_id` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`c_id` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '',
`s_score` int(3) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES ('1', '1', 80);
INSERT INTO `score` VALUES ('1', '2', 90);
INSERT INTO `score` VALUES ('1', '3', 99);
INSERT INTO `score` VALUES ('2', '1', 70);
INSERT INTO `score` VALUES ('2', '3', 60);
INSERT INTO `score` VALUES ('2', '4', 80);
INSERT INTO `score` VALUES ('3', '1', 80);
INSERT INTO `score` VALUES ('3', '1', 80);
INSERT INTO `score` VALUES ('3', '3', 80);
INSERT INTO `score` VALUES ('4', '1', 50);
INSERT INTO `score` VALUES ('4', '2', 30);
INSERT INTO `score` VALUES ('4', '3', 20);
INSERT INTO `score` VALUES ('5', '1', 76);
INSERT INTO `score` VALUES ('5', '2', 87);
INSERT INTO `score` VALUES ('6', '1', 31);
INSERT INTO `score` VALUES ('6', '3', 34);
INSERT INTO `score` VALUES ('7', '2', 89);
INSERT INTO `score` VALUES ('7', '3', 98);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`s_name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`s_code` int(100) NULL DEFAULT NULL,
`s_sex` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`s_birth` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `普通索引`(`s_sex`) USING BTREE,
INDEX `联合索引`(`s_name`, `s_code`, `s_birth`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '学生1', 1, '男', '2022-11-20');
INSERT INTO `student` VALUES (2, '学生2', 2, '男', '2022-11-20');
INSERT INTO `student` VALUES (3, '变成派大星', 3, '男', '2022-11-20');
INSERT INTO `student` VALUES (4, '学生4', 4, '男', '2022-11-20');
INSERT INTO `student` VALUES (5, '学生5', 5, '女', '2022-11-20');
INSERT INTO `student` VALUES (6, '学生6', 6, '女', '2022-11-20');
INSERT INTO `student` VALUES (7, '学生7', 7, '女', '2022-11-20');
-- ----------------------------
-- Table structure for teacher
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`t_id` int(11) NOT NULL AUTO_INCREMENT,
`t_name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`t_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of teacher
-- ----------------------------
INSERT INTO `teacher` VALUES (1, '泡芙教师');
INSERT INTO `teacher` VALUES (2, '蟹老板');
INSERT INTO `teacher` VALUES (3, '章鱼哥');
SET FOREIGN_KEY_CHECKS = 1;
表对应联系:

问题
查询”1″课程比”2″课程成果高的学生的信息及课程分数
示例图:

剖析
这个问题 便是 学生表student 和 成果表 score 之间的相关 首要的话咱们能够剖析出来 课程1 比 课程 2 成果高的 这个便是在成果表中机型操作 之前文章说过 一张表中呈现比较第一反响便是尝试 自衔接 所以咱们第一步是自衔接
1、成果表自衔接
select * from score sc1,score sc2
2、参加一些过滤条件
这儿自衔接需要带上一些条件
- 课程 1 和 课程 2 咱们只需要看这两门课程的数据 也便是表一保留课程1 表二保留课程2 方便比较 翻译SQl 句子 ===》
sc1.c_id = 1 and sc2.c_id = 2 - 课程 1 成果 大于课程 2 翻译SQl ===》
select * from score sc1,score sc2 where sc1.c_id = 1 and sc2.c_id = 2 and sc1.s_score > sc2.s_score - 同学的信息 肯定是同一个人的 课程1 成果 大于课程2 成果 所以加上条件
sc1.s_id = sc2.s_id
生成SQl 句子
select * from score sc1,score sc2 where sc1.c_id = 1 and sc2.c_id = 2 and sc1.s_score > sc2.s_score and
sc1.s_id = sc2.s_id

咱们只需要 s_id 和 s_score 精简之后

这个时候咱们只需要拿到学生信息就行了 咱们有s_id 拿到学生信息岂不是易如反掌
3、衔接学生表
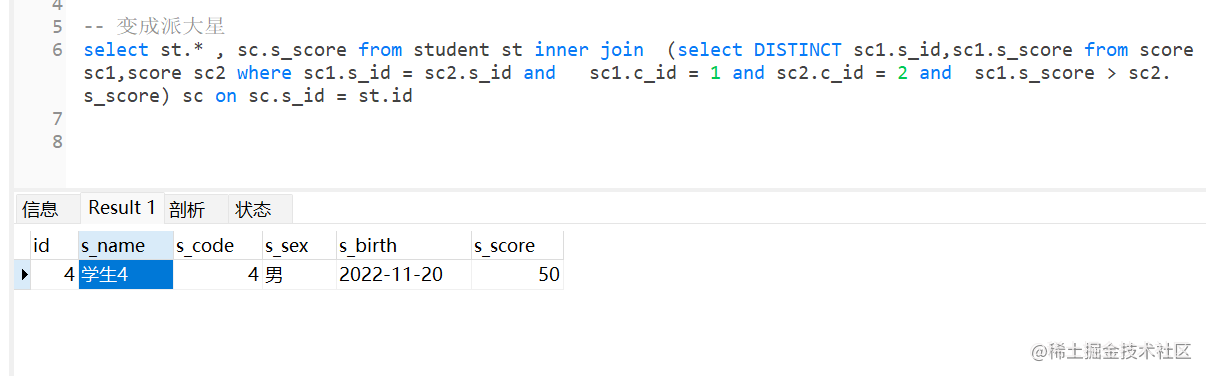
select st.* , sc.s_score from student st inner join (select DISTINCT sc1.s_id,sc1.s_score from score sc1,score sc2 where sc1.s_id = sc2.s_id and sc1.c_id = 1 and sc2.c_id = 2 and sc1.s_score > sc2.s_score) sc on sc.s_id = st.id
得到输出结果

答案
知识点
- 表之间的自衔接
- 内衔接
- 子查询
还有一种题解 就不具体解说了 能够直接看看答案思考一下
select a.*,b.s_score as score FROM student a inner JOIN score b ON a.id = b.s_id and b.c_id= 1
LEFT JOIN score c on a.id=c.s_id and c.c_id= 2 or c.c_id = NULL
WHERE b.s_score>c.s_score
知识点
- 内衔接
- 左衔接
其实差不多基本都是一个思路
本文结束 后续继续更新相关SQL思维训练 可重视专栏或许重视自己
欢迎检查SQL 专栏 查漏补缺 指导一二
引荐阅读相关文章:小白也能看到索引的运用和规则
本文正在参加「技能专题19期 闲谈数据库技能」活动