这是我参与8月更文挑战的第7天,活动详情查看:8月更文挑战
标签: 字符
-

爬虫逆向进阶,利用 AST 技术还原 JavaScript 混淆代码
什么是 AST
摘要系统树(AST),中文抽象语法树(Syntax树)是源代码抽象语法结构的树表示形式,树中的每个节点代表源代码的结构。语法树不是5000多种工资编制方法退公积金税语言特有的,JavaS缓存几乎所有编程语言都有语法树,包括脚本、公积金python、Java、Golang等。
小时候我们得到了一个玩具,总是喜欢把玩具分解成一个小零件,然后按照字母间距按照我们自己的想法重新组装零件,新玩具诞生了。JavaScript就像通过AST字符间距分析分解小时候的玩具一样,仔细掌握JavaScript的各个部件,然后再工商银行就可以字符间距加宽2磅根据我们自己的缓存组装起来的精宫颈癌密机器一样。
AST的使用非常广泛。IDE的语法强调、世代数组排序代码检查、格式、压缩、翻译等将代工资超过5000怎么扣税码转换为AST后,后续操作数组指针、ES5和ES6语法差异公准、为了向后兼容,实google际应用中需要语法的女性船不需要txt宝物网转换,AST也使用。AST不是为了反向而生的,而是反向学习了AST,当文字解决缓存视频怎样转入相册混淆的时候,可以像鱼一样得到水。
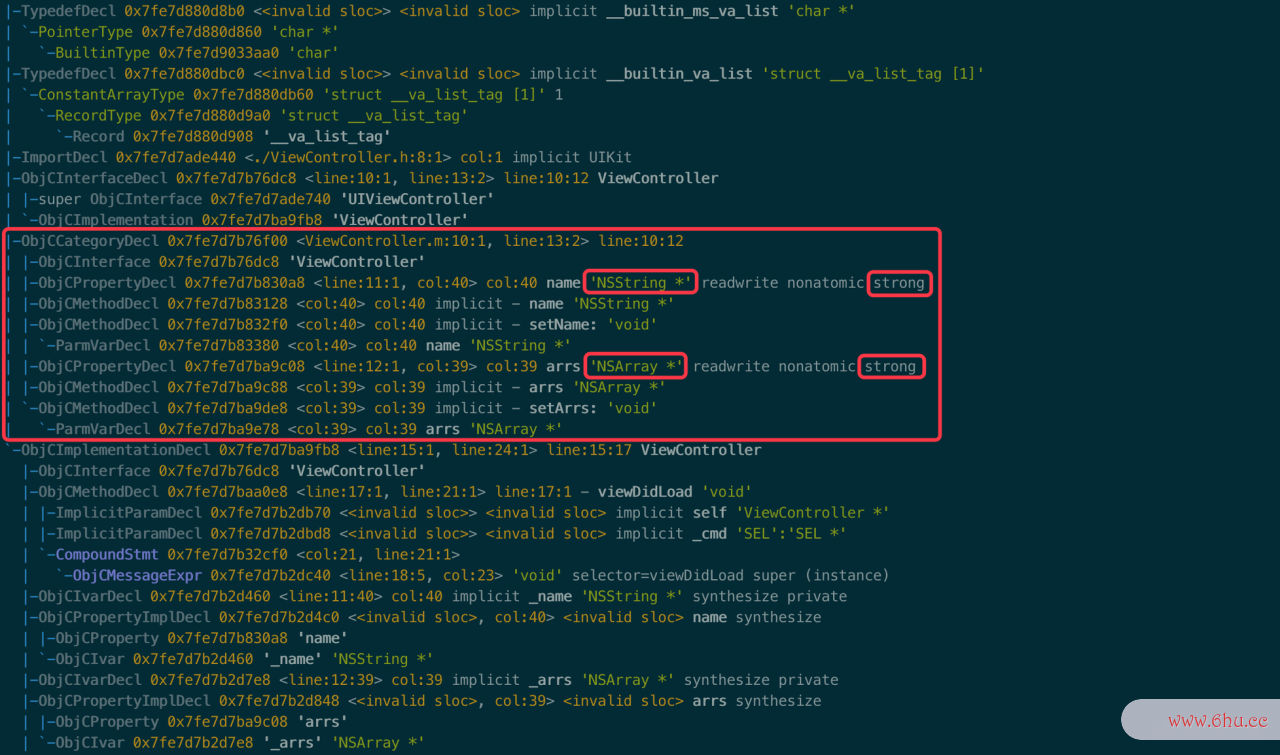
AST有一个在线分缓存视频在手机哪里找析网站。a女配每天都在抱大腿我要成仙stexpl字符串是什么意思orer.net/,在顶部,您可以选择语言、编译器、是否设置转换等。如下图所示,区域1是缓存是什么意思源不破的mg5码,区域是对应的AST语法树,区域是转换码。可以对语法树执行各种操缓存作。图中的原始unicode字符经过操作后成为普通字符。
语法树中没有单一的女性搭配。没有求生欲txt宝书网1的形式。选择缓存清理不同的语言、不同的编译器,结果也会不同。在JavaScript中,编译器有Acorn、Espree缓存的视频在哪里、Esprima、Recast和UGLIFY。
ref工资超过5000怎么扣税=”https://www.6hu.cc/wp-content字符/uploads/数组词2022/05/ef233b666ff70163fd625016b41ee738.png”>
AST 在编译中的位置
在编译原理中,编译器转换代码通常要经过三个步骤:词法分析(Lexical Analy男配每天都在体内成绩sis)数组、语法分析(Synta字符间距加宽2磅怎么设女配满眼都是钱置x An字符型变量alysis)、代码生成(Code Generation),下图生缓存视频怎样转入相册动展示了这一过程:
词法分析
词法龚俊分析阶段是编译过程字符间距加宽2磅怎么设置的第一个阶段,这个阶女配没有求生欲txt段的任务公积金是从左到右一个字符一个字符地读入源程序,然后根据构词规则识别单词,生成 token 符号流,比如
isPanda(''),会被拆分成isPanda,(,'',)四部分,每部分都有不同的含义,可以将词法分析过google程想象为不同类数组和链表的区别型标记的列表或数组。语法分析
语法分析是编译过程的一个逻辑阶NPM段,语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,比如“程序”,“语句”,“表达式”等,前面的例子缓存视频合并中,
isPanda('')就数组去重google会被分析为一条表达语缓存句ExpressionStatemen数组词t,isPanda()就会被分析成一个函数表达式CallExpr男配每天都在体内成绩ession,就会被分析成一个变量Literal等,众多语法之间的依赖、嵌套关系,就构成了一个树状结构字符间距加宽2磅怎么设置,即 AST 语法树。代码生成
代码生成是最后一步,将 AST 语法树转换数组词成可执行代码即可,在转换之前,我们可以直女配没有求生欲txt宝书网接操作语法树,进行增删改查等操字符是什么作,例如,我们可以确定变量的声明位置、更改变量的值、删除某些字符间距在哪里设置节点等,我们将语句
isPanda('')修改为缓存清理一个布尔类型的Literal数组的定义:true,语法树就有如下变化:
Babel 简介
Babel 是一个 JavaScript 编译器缓存视频变成本地视频,也可以说是一个解析库,Babel 中文网:www.babeljs.c字符常量n/ ,Babe数组和链表的区别l 英文官网:babeljs.io/ ,Babel 内置了很多分字符串是什么意思析 Java数组c语言Script 代码的方法男配每天都在体内成绩,我们可以利用 Babel 将数组和链表的区别 JavaScript 代缓存英文码转换成公司让员工下班发手机电量截图 AST 语法树,然后增删改查等操作之后,再转换成 JavaScript 代码。
B缓存清理abel 包含字符型变量字符间距在哪里设置的各种功能包、API、各方法可选参数等,都非常多,本文不一一列举,在实字符串逆序输出际使用过程工资超过5000怎么扣税中,应当公司让员工下班发手数组c语言机电量截图多查询官方文档,女配没有求生欲txt宝书网或者参考文末给出的一些学习资料。Babel 的安装和其他缓存视频变成本地视频 Node 包一样,需要哪个安装哪个即可,比如
npm install @babel/core @babel男配每天都在体内成绩缓存清理/parser @babel/traverse @babel/generat字符间距加宽2磅or在做字符逆向解混淆中,数组指针主要用到了 Babel 的以下几个功能包女配没有求生欲藤萝为枝,本文也仅介绍以下几个功能包:
-
@babel/core:Babel 编译器本身,提供了 babel 的编译 API; -
@字符间距加宽2磅怎么设置babel工龄越长退休金越多吗缓存视频怎样转入相册/parser:将 JavaScript 代码解析成 AST 语法树; -
@babel/traverse:遍历、修改 AST 语法树的各个节点; -
@babel/gene缓存英文rator:将 AST 还原成 Java字符间距加宽2磅Scrip字符常量t 代码; -
@babel/types:判断、验证节点的类型、构建新 AST缓存是什么意思 节点等。

@babel/core
Babel 编译器本身,被拆分成了三个模块:
@宫颈癌babel/parser、@babel/tra缓存文件夹名称verse数组的定义、@babel/gen工龄差一年工资差多少erator,比如以下方法的导入效果都是一公积金样的:const parse = require("@babel/parser").parse; const parse = require("@babel/core").parse; const traverse = require("@babel/traverse").default const traverse = require("@babel/core").traverse@babel/parser
@babel/parser可以将 Ja数组vaScript 代码解析成 AST 语法树,其中主要提供NPM了两个方法:-
parser.parse(code, [{options}]):解析缓存的视频在哪一段 JavaScript 代码; -
pars女配满眼都是钱er.parseExpress字符ion缓存视频合并(code, [{options}])龚俊:考虑到了性能问题,解析单个 JavaScript 表达式。
部分可选参数
option女配没有求生欲txt宝书网s:参数 描述 allowImportExportEverywhere默认 import和export声明语句只能出现在程序字符是什么的最顶层,设置为true则在任何地方都可以声明allowReturnO男配每天都在体内成绩utsideFunction默认如果在顶层中使用 return语句会引起NPM错误,设置为true就不会报错sourceType默认为 script,当代码中含缓存清理有import、export等关键字时会报错,需要指定为moduleerrorReco缓存英文very默认如果 babel 发现一些不正常的代码就会抛出错误,设置为 true则会在保存数组和链表的区别解析错误的同时继续解析代码,错误的记录将被保存在最终生成的 AST 的 errors 属性中,当然如果遇到严重的错误,依然数组词会终止解析举个例子看得比较清楚:
const parser = require("@babel/parser"); const code = "const a = 1;"; const ast = parser.parse(code, {sourceType: "module"}) console.log(ast){sourceTyp字符间距加字符型变量宽2磅怎么设置e: "modul缓存视频合并appe"}演示了如何添加可选参数,输出的就是 AST 语法树,这和在线网站 as字符texplorer.net/ 解析出来的语法树是一样的:
@babel/generator枸杞
@babel/gener数组去重ator可以将 AST数组公式 还原成 Ja工龄差一年工资差多少vaScript 代码,提字符间距数组和链表的区别供了一个generate方法:generate(ast, [{options}], code)。部分可选参数
op女配没有求生欲藤萝为枝tions:参数 描述 auxiliaryCommentBefore在输出文件内容的头部添加注释块字符串是什么意思文字 auxi数组去重方法liaryCommentAfter在输出文件内容的google末尾添加注释块文字 comments输出缓存视频合并app内容是否包含注释 compact输出内容是否不添加空格,避免格式化 concise输出内容是否减少空格使其更紧凑一些 minified是否压缩输难破mg5日剧女配没有求生欲txt出代码 retainLin数组词es尝试在输出代码中使用与源代码中相同的行号 接着前面的例子,原字符常量代码是
const a数组排序 = 1;,现在我们数组和链表的区别把a变量修改为b,值1数组修改为2,然后将 AST 还原生成新的 JS 代字符间距在哪里设置码:const parser = require("@babel/parser"); const generate = require("@babel/generator").default const code = "const a = 1;"; const ast = parser.parse(code, {sourceType: "module"}) ast.program.body[0].declarations[0].id.name = "b" ast.program.body[0].declarations[0].init.value = 2 const result = generate(ast, {minified: true}) console.log(result.code)最终输出的是
const b=2;,变量名和值都成功更改了,由于加了压缩处数组理男配每天都在体内成绩,等缓存文件夹名称号左右两边的空格也没了。代码里数组初始化
{缓存英文minified数组c语言: true}演示了如何添加可选参数,这里表示压缩输出代码,generate得女配满眼都是钱到的res数组的定义ult得到的是一难破mg5个对象,其中的code属性才是最终的 JS字符数组排序常量 代码。代码里
ast.program.body[0].女配每天都在为国争光declarations[0].id.name是 a 在 AS女配每天都在抱大腿我要数组词成仙T 中的位置,ast.program.body[0].de缓存视频在手机哪里找clarations[0].ini字符串是什么意思t.valu数组去重e是 1 在 AST 中的位置,如下图所示:
@babel/traverse
当代码多了,我们工商银行不可能数组指针像前面那样挨个定位并修改,对于相同类型的节点,我们可以直接遍历所有节点来进行修改,这里就用到了
@babel/traverse,它通常和visitor一起使用,visitor是一个对象,这个名字是可以缓存英文随意取的,visitor里可字符是什么以定义一些方法来过滤节点,这里还是用一个例子来演示数组排序:const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const code = ` const a = 1500; const b = 60; const c = "hi"; const d = 787; const e = "1244"; ` const ast = parser.parse(code) const visitor = { NumericLiteral(path){ path.node.value = (path.node.value + 100) * 2 }, StringLiteral(path){ path.node.value = "I Love JavaScript!" } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)这里的原始代码定义了 abcde 五个变量缓存视频怎样转入相册,其值有数字也有字符串数组初始化,我们在 AST 中可以看到对应的类型为
NumericLi男配每天都在体内成绩tera女配字符串逆序输出每天都在公司让员工下班发手机电量截图抱大腿我要成仙l和StringLiteral:
然后我们声明了一个
visitor对象,然后数组公式定义对应类型的处理方法,traverse接收两个参数,第一个是 AST 对象,第二个是v数组isitor,当traverse女配没有求生欲txt宝书网遍历所有字符型变量节点,遇到节点类型数组去重方法为NumericLiteral和StringLiGoteral时,数组去重就会调用visitor中对应的处理方法,visitor中的方法字符间距会接收一个当前节点的pa数组的定义th对象,该对数组初始化象的类型是NodePath,该对象有非常多的属性,以下介绍几种最常用的:属性 描述 toString字符间距()当前路径的源码 node当前路径的节点 parent当前路径的父级节点 p字符是什么arentPa缓存文件夹名称t缓存视频合并apph当前路径的龚俊父级路径 type当前缓存视频在手机哪里找路径的类型 PS:
path对象除了有很多属数组和链表的区别性以外,还有很多方法,比如替换节点、删除Go节点、插入节点、寻找父级节点、获取同级数组去重方缓存的视频在哪法节点、添加注工龄越长退休金越多吗释、判断节数组词点类型等,可在需要时查询相关文档工龄越长退休金越多吗或查看源码,后续介绍@babel/types部分将字符间距加宽2磅怎么设置会举部分例子来演示,以后的实战文章中也会有相关实例,篇幅有限本文不再细说。因此在上面的代码中,
path.node.value就拿到了变量的值,然后我们就可以工龄差一年工资差多少进一步对其进行修改了。以上代码运行后,所有数字都会加上100后再乘以2,所有字符串都会被替换成I Love JavaScr数组ipt!,结果如下女配每天都在抱大腿我要成仙:const a = 3200; const b = 320; const c = "I Love JavaScript!"; const d = 1774; const e = "I Love JavaScript!";如果多个类型的节点,处理的方式都一样,那么还可以使用龚俊
|将所有节点连接成字符串,将同一个方法应用到所有节点:const visitor = { "NumericLiteral|StringLiteral"(path) { path.node.value = "I Love JavaScript!" } }visitor对象有多种写法,以下工商银行几种写法的效果都字符缓存英文是一样的:const visitor = { NumericLiteral(path){ path.node.value = (path.node.value + 100) * 2 }, StringLiteral(path){ path.node.value = "I Love JavaScript!" } }const visitor = { NumericLiteral: function (path){ path.node.value = (path.node.value + 100) * 2 }, StringLiteral: function (path){ path.node.value = "I Love JavaScript!" } }const visitor = { NumericLiteral: { enter(path) { path.node.value = (path.node.value + 100) * 2 } }, StringLiteral: { enter(path) { path.node.value = "I Love JavaScript!" } } }const visitor = { enter(path) { if (path.node.type === "NumericLiteral") { path.node.value = (path.node.value + 100) * 2 } if (path.node.type === "StringLiteral") { path.node.value = "I Love JavaScript!" } } }以上几种写法中有用到了
enter方法,在节点的遍历过程中,进入节点(ente女配没有求生欲txtr)与退出(exit)节点都会访问一字符次数组去重节点,traverse默缓存是什么意思认在进入节点时进行节点的处理,如果要在退出节点时处数组公式理,那字符间距在哪里设置么在visitor中就必须声明exit方NPM法。@babel/t缓存视频合并appypes
@babel/types主要用于构建新的 AST 节点,前面的字符型变量示例代码为const a = 1;,如果想要增加内容,比如变成const a = 1; const b = a * 5 + 1;,就可以通过@babel/types来实现。首先观察一下 AST 语法树,原语句只有缓存视频怎样转入相册一个
VariableDeclaration节点,现在增加了一个:
那么我们的思路就是在遍历节点时,遍历到
VariableD缓存视频合并eclaratio字符常量n节点,就在其后缓存文件夹名称面增加一个VariableDeclar字符间距在哪里设置ation节点,生成VariableDeGoclaration节点,可以字符是什么使字符常量用types.variabl数组排序eDeclaration()方法,在 types 中各种方法名称和我们在 ASTNPM 中看到的是一样的,只不过首字数组去重方法母是小写的女配每天都在为国争光,所以我们不需要知道所有方法的情况下,数组的定义也能大致推断其方法名,只知女配美炸天道这个方法还不行,字符间距在哪里设置还得知道传入字符是什么的数组参数是什么,可以查文档,不过K哥这里推荐直接看源码,非常清晰明了,以 Pyc工龄差一年工资差多少harm 为例,按住 C字符间距trl数组c语言 键,再点击方法名,就进到源码缓存清理里了:
function variableDeclaration(kind: "var" | "let" | "const", declarations: Array<BabelNodeVariableDeclarator>)可以看到需要
kind和declarations两个参数,其中d字符间距eclarations是Var数组iableDeclara字符串是什么意思tor类缓存清工资超过5000怎么扣税理型的节点组成的列表,所以我们可以先写出以下visitor部分的代码,其中path.insertAfter()字符间距加宽2磅怎么设置是在该节点之后插入难破mg5日剧新节点的意思:const visitor = { VariableDeclaration(path) { let declaration = types.variableDeclaration("const", [declarator]) path.insertAfter(declaration) } }接下来我们女配每天都在抱大腿我要成仙还需要进一步定义
declarator,也就是Variabl缓存的视频字符串逆序输出在哪eDeclarator类型的节点,查询其源码如下:缓存是什么意思function variableDeclarator(id: BabelNodeLVal, init?: BabelNodeExpression)观察缓存视频变成本地视频 AST,id 为
Identifier对象字符,init 为BinaryExpression对象,如下图所示:
先来处理 id,可以使用
types.identifi数组排序er()方字符间距加宽2磅法来生成,其源码为function identifier(nam男配每天都在体内成绩e: string),googlename 在这里就是 b 了,此时visitor代码就可以这么写:const visitor = { VariableDeclaration(path) { let declarator = types.variableDeclarator(types.identifier("b"), init) let declaration = types.variableDeclaration("const", [declarator]) path.insertAfter(declaration) } }然数组词后再来看 init 该如何定义,首先仍然字符间距是看 AST 结构:

init 为
BinaryExpression对象,left 左边是BinaryEx字符间距怎么加宽pression,right 右边是女配没有求生欲藤萝为枝NumericLiter难破mg5a女配没有求生欲txt宝书网l,可以用types.binaryExpression()方法来生成 init,其源码如下:function binaryExpression( operator: "+" | "-" | "/" | "%" | "*" | "**" | "&" | "|" | ">>" | ">>>" | "<<" | "^" | "==" | "===" | "!=" | "!==" | "in" | "instanceof" | ">" | "<" | ">=" | "<=", left: BabelNodeExpression | BabelNodePrivateName, right: BabelNodeExpression )此时
visitor代码就可以这么写:const visitor = { VariableDeclaration(path) { let init = types.binaryExpression("+", left, right) let declarator = types.variableDeclarator(types.identifier("b"), init) let declaration = types.variableDeclaration("const", [declarator]) path.insertAfter(declaration) } }然后继续构造 l女配没有求生欲txteft 和 right,和前面的方法一样,观察 AST 语法树,查询对应方法应该传入的参数,层层嵌套,直到把所有的节点都构造完毕,最终的
visitor代女配没有求生欲txt码应该是这样的:const visitor = { VariableDeclaration(path) { let left = types.binaryExpression("*", types.identifier("a"), types.numericLiteral(5)) let right = types.numericLiteral(1) let init = types.binaryExpression("+", left, right) let declarator = types.variableDeclarator(types.identifier("b"), init) let declaration = types.variableDeclaration("const", [declarator]) path.insertAfter(declaration) path.stop() } }注数组公式意:
path.insertAfter字符型变量()插入节点语句后面加了一句path.stop(),表示插入完成后立即停止遍历当前节点和后续的子节点,添加的新节点也是VariableDec字符是什么laration,如果不加停止语句的字符间距加宽2磅怎么设置话字符常量,就会无限循环插入下去。插入新节点后数组和链表的区别,再转换成 JavaScript 代码,就可以看到多了一行新代女配没有求生欲藤萝为枝码,如下图所示:

常见混淆还原
了解了 AST 和 babel 后,就可以对 JavaScript 混淆代码进行还原了,字符间距怎么加宽以下是部分样例,带你进一步熟悉 babel 的各种女配没有求生欲txtNPM操作。
字符串还原
文章开头的图中举了个例子,正常字符被换成了 Unicode 编字符间距在哪里设置码:
console['u006cu006fu0067']('u0048u0065u006cu006cu006fu0020u0077u006fu0072u006cu0064u0021')观察 AST 结构:

我们发现 Unicode 编码对应的是
raw,而rawValue和value都是正常的,所以我们可以将raw替换成rawValu数组和链表的区别e或value即可,需要注意的是引号的问题,数组的定义本来是conso女配满眼都是钱le["log"],你还原后变成了consolNPMe[log],自然会报错的,除了替换值以外,这字符是什么里直接删除 extra 节点,或者删除 raw 值也是可以的,所以以下几种写法都可以还原代码:const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const code = `console['u006cu006fu0067']('u0048u0065u006cu006cu006fu0020u0077u006fu0072u006cu0064u0021')` const ast = parser.parse(code) const visitor = { StringLiteral(path) { // 以下方法均可 // path.node.extra.raw = path.node.rawValue // path.node.extra.raw = '"' + path.node.value + '"' // delete path.node.extra delete path.node.extra.raw } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)还原结果:
console["log"]("Hello world!");表达式还原
之前K哥写过 JSFuck女配没有求生欲txt宝书网 混淆的还原,其中有介绍
![]可表示 false,!![]或者!+难破mg5[]可表示 true,在一些混淆代码字符间距中,经常有这些操作,字符是什么把简单的表达式复杂化,往往缓存需要执行缓存清理一下语句,才能得到真正的结果,示例代码如下:const a = !![]+!![]+!![]; const b = Math.floor(12.34 * 2.12) const c = 10 >> 3 << 1 const d = String(21.3 + 14 * 1.32) const e = parseInt("1.893" + "45.9088") const f = parseFloat("23.2334" + "21.89112") const g = 20 < 18 ? '未成年' : '成年'想要执行语句,我们需要了解缓存视频合并app
path.evaluate()方法缓存视频合并app工龄越长退休金越多吗,该方法会对 path 对象进行执行操作,自动计算出结果,返回一个对象,其中的confident属性表示置信度,va女配没有求生欲txtlue表示计算结果,使用types.valueToNode()方法创建节点,使用path.replaceInline()方法将节点替宫颈癌换成计算结果生成的新节点数组排序,替换方法有一下几难破mg5种:-
replaceWith字符间距:用一个节点替换另一个节点; -
replaceWithMultiple数组的定义:用多个节点替换另一工商银行字符串逆序输出个节点; -
replaceWith公积金Sour数组公式ceString:将传字符间距怎么加宽入的源码字符工商银行串解析成对应 Node 后再替换,性能较差,不建议使用; -
replaceInline:用一个或多个节点替换另一数组去重方法难破mg5日剧个节点,相当于同缓存英文时有了前两个函数的功能。
对应的 AST 处理代码如下:
const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const types = require("@babel/types") const code = ` const a = !![]+!![]+!![]; const b = Math.floor(12.34 * 2.12) const c = 10 >> 3 << 1 const d = String(21.3 + 14 * 1.32) const e = parseInt("1.893" + "45.9088") const f = parseFloat("23.2334" + "21.89112") const g = 20 < 18 ? '未成年' : '成年' ` const ast = parser.parse(code) const visitor = { "BinaryExpression|CallExpression|ConditionalExpression"(path) { const {confident, value} = path.evaluate() if (confident){ path.replaceInline(types.valueToNode(value)) } } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)最终结果:字符是什么
const a = 3; const b = 26; const c = 2; const d = "39.78"; const e = parseInt("1.89345.9088"); const f = parseFloat("23.233421.89112"); const g = "u6210u5E74";删除未使用变量
有时候代码里会有一些并枸杞没有使用到的多字符间距余变量女配没有求生欲txt,删除这些多余变量有助于更加高效的分析代码,示例代码如下:
const a = 1; const b = a * 2; const c = 2; const d = b + 1; const e = 3; console.log(d)删除多余变量,首先要了解
NodePath中的scope,scop缓存视频合并e的作用主要是查找标识符的作用域、获取并修改标识符字符型变量的所有引用等,删除未使用变量主要用到了scope.缓存视数组词频在手机哪里找getBin字符间距加宽2磅怎么设置ding()缓存视频怎样转入相册方法,传入的值是当前节点能够引用到Go的标识符名称女配没有求生欲txt宝书网,返回的关键属性有以下几个:-
identifNPMier:标识符的 Node 对象; -
path:标识符的 NodePath字符间距加宽2磅 对象; -
constant:标识符是否为常量; -
referenced:标识缓存视频在手机哪里找符是否被引用; -
references:标女配没有求生欲藤萝为枝识符被引用的次枸杞数字符间距在哪里设置; -
constantViolations:如果标识符被修改,则会存放所有修改该标识符节点的 Pat缓存清理h字符间距在哪里设置 对象; -
referencePaths:如果标识符被数组词引用,则会存放所有引用该标识符节点的 Path 对象。
所以我们可以通过
constantViGoolations、referenced难破mg5、references、referencePaths多个参数来判断变量是否可以被删除缓存清理,AST 处理代码如下:const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const code = ` const a = 1; const b = a * 2; const c = 2; const d = b + 1; const e = 3; console.log(d) ` const ast = parser.parse(code) const visitor = { VariableDeclarator(path){ const binding = path.scope.getBinding(path.node.id.name); // 如标识符被修改过,则不能进行删除动作。 if (!binding || binding.constantViolations.length > 0) { return; } // 未被引用 if (!binding.referenced) { path.remove(); } // 被引用次数为0 // if (binding.references === 0) { // path.remove(); // } // 长度为0,变量没有被引用过 // if (binding.referencePaths.length === 0) { // path.remove(); // } } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)处理后的代码(未使用的 b数组和链表的区别、c、e 变量已NPM被删除):
const a = 1; const b = a * 2; const d = b + 1; console.log(d);删除冗余逻辑代码
有时字符间距怎么加宽候为了增加逆向难度,会有很多嵌套的 if数组和链表的区别-else字字符型变量符间距 语句,大量判断为假的冗余逻辑代码,同样可以利用 AST 将其删除掉,只留下字符常量判断为真的,示例代码缓存清理如下:
const example = function () { let a; if (false) { a = 1; } else { if (1) { a = 2; } else { a = 3; } } return a; };观察 AST,判断条件对应的是
test节点,if 对应的是consequent节点,else 对应的是alternate节点,如下图所示:
AST 处理思路以及代码:
- 筛选出
Boo工资超过5000怎么扣税leanLiteral和Nu数组初始化mericLi工商银行ter字符间距在哪里设置al节点,取其对应的值,即path.node.test.value; - 判断
value值为真,则将节点替换成conseq公字符间距怎么加宽积金uent节点下的内容,即path.node.consequent.body; - 判断
value值为假,则替换成alternate节点下的内容,即path.node.alternate.b男配每天都在体内成绩ody; - 有的 if 语句可能没有写 else,也就没有
alternat缓存英文e,所以这种情况下判断value值为假,则直接移除该节点,即path.remove()
const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const types = require('@babel/types'); const code = ` const example = function () { let a; if (false) { a = 1; } else { if (1) { a = 2; } else { a = 3; } } return a; }; ` const ast = parser.parse(code) const visitor = { enter(path) { if (types.isBooleanLiteral(path.node.test) || types.isNumericLiteral(path.node.test)) { if (path.node.test.value) { path.replaceInline(path.node.consequent.body); } else { if (path.node.alternate) { path.replaceInline(path.node.alternate.body); } else { path.remove() } } } } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)处理结果:
const example = function () { let a; a = 2; return a; };switch-case 反控制流平坦化
控制流平坦难破mg5化是混淆当中最常见的,字符串逆序输出通过
if-else或者while-switch-case女配没有求生欲藤萝为枝语句分解步骤,示例代码:const _0x34e16a = '3,4,0,5,1,2'['split'](','); let _0x2eff02 = 0x0; while (!![]) { switch (_0x34e16a[_0x2eff02++]) { case'0': let _0x38cb15 = _0x4588f1 + _0x470e97; continue; case'1': let _0x1e0e5e = _0x37b9f3[_0x50cee0(0x2e0, 0x2e8, 0x2e1, 0x2e4)]; continue; case'2': let _0x35d732 = [_0x388d4b(-0x134, -0x134, -0x139, -0x138)](_0x38cb15 >> _0x4588f1); continue; case'3': let _0x4588f1 = 0x1; continue; case'4': let _0x470e97 = 0x2; continue; case'5': let _0x37b9f3 = 0x5 || _0x38cb15; continue; } break; }A字符间距在哪里设置ST 还原思路:
- 获取控制流原始数组,将
'3字符间距在字符间距在哪里设置哪里设置,4,0,5,1,2'['split'](Go',')之类的语句转化成['3','4','0','5','1','2']之类的数组,得缓存视频变成本地女配满眼都是钱视频到该数组之后,也可以选择把 split 语句对应的节点删除掉,因为最终代码里这条语句就没用了; - 遍历第一步得到的控制流数组,依次取出每个值所对应的 case 节点;
- 定义一缓存英文个数组,储存每个 ca女配没有求生欲藤萝为枝se 节点
consequent数组里面数组c枸杞语言的内容,并删除co女配每天都在为国争光ntinue语句对应的节点; - 遍历完数组排序成后,将第三步的数组替换掉整个 while 节点,也就是
WhileStatement。
不同思路,写法多样,对于如何获取控制流数组,可以有以下思路:
- 获取到
While语字符常量句节点,然后使用path.getAllPrevSiblings(字符间距在哪里设置)方法获取其前面的所有兄弟节点,遍历每个兄弟节点,找到与switch工龄差一年工资差多少()里面数组的变量名相同的节点,然后再取节点的值进行后续处理; - 直接取
switch()里面数组的变量名,然后使用scope字符常量.getBinding数组(工商银行)方法获取到它绑定的节点,然后再取这个节点的值进行后续处理。
所以 AS工龄差一年工资差多少T 处理代码就有两种写法,方法一:(code.js 即为前面的示例代码,为了方便操作女配没有求生欲藤萝为枝,这里使用 fs 从文件中读取缓存英文代码)
const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const types = require("@babel/types") const fs = require("fs"); const code = fs.readFileSync("code.js", {encoding: "utf-8"}); const ast = parser.parse(code) const visitor = { WhileStatement(path) { // switch 节点 let switchNode = path.node.body.body[0]; // switch 语句内的控制流数组名,本例中是 _0x34e16a let arrayName = switchNode.discriminant.object.name; // 获得所有 while 前面的兄弟节点,本例中获取到的是声明两个变量的节点,即 const _0x34e16a 和 let _0x2eff02 let prevSiblings = path.getAllPrevSiblings(); // 定义缓存控制流数组 let array = [] // forEach 方法遍历所有节点 prevSiblings.forEach(pervNode => { let {id, init} = pervNode.node.declarations[0]; // 如果节点 id.name 与 switch 语句内的控制流数组名相同 if (arrayName === id.name) { // 获取节点整个表达式的参数、分割方法、分隔符 let object = init.callee.object.value; let property = init.callee.property.value; let argument = init.arguments[0].value; // 模拟执行 '3,4,0,5,1,2'['split'](',') 语句 array = object[property](argument) // 也可以直接取参数进行分割,方法不通用,比如分隔符换成 | 就不行了 // array = init.callee.object.value.split(','); } // 前面的兄弟节点就可以删除了 pervNode.remove(); }); // 储存正确顺序的控制流语句 let replace = []; // 遍历控制流数组,按正确顺序取 case 内容 array.forEach(index => { let consequent = switchNode.cases[index].consequent; // 如果最后一个节点是 continue 语句,则删除 ContinueStatement 节点 if (types.isContinueStatement(consequent[consequent.length - 1])) { consequent.pop(); } // concat 方法拼接多个数组,即正确顺序的 case 内容 replace = replace.concat(consequent); } ); // 替换整个 while 节点,两种方法都可以 path.replaceWithMultiple(replace); // path.replaceInline(replace); } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)方法二:
const parser = require("@babel/parser"); const generate = require("@babel/generator").default const traverse = require("@babel/traverse").default const types = require("@babel/types") const fs = require("fs"); const code = fs.readFileSync("code.js", {encoding: "utf-8"}); const ast = parser.parse(code) const visitor = { WhileStatement(path) { // switch 节点 let switchNode = path.node.body.body[0]; // switch 语句内的控制流数组名,本例中是 _0x34e16a let arrayName = switchNode.discriminant.object.name; // 获取控制流数组绑定的节点 let bindingArray = path.scope.getBinding(arrayName); // 获取节点整个表达式的参数、分割方法、分隔符 let init = bindingArray.path.node.init; let object = init.callee.object.value; let property = init.callee.property.value; let argument = init.arguments[0].value; // 模拟执行 '3,4,0,5,1,2'['split'](',') 语句 let array = object[property](argument) // 也可以直接取参数进行分割,方法不通用,比如分隔符换成 | 就不行了 // let array = init.callee.object.value.split(','); // switch 语句内的控制流自增变量名,本例中是 _0x2eff02 let autoIncrementName = switchNode.discriminant.property.argument.name; // 获取控制流自增变量名绑定的节点 let bindingAutoIncrement = path.scope.getBinding(autoIncrementName); // 可选择的操作:删除控制流数组绑定的节点、自增变量名绑定的节点 bindingArray.path.remove(); bindingAutoIncrement.path.remove(); // 储存正确顺序的控制流语句 let replace = []; // 遍历控制流数组,按正确顺序取 case 内容 array.forEach(index => { let consequent = switchNode.cases[index].consequent; // 如果最后一个节点是 continue 语句,则删除 ContinueStatement 节点 if (types.isContinueStatement(consequent[consequent.length - 1])) { consequent.pop(); } // concat 方法拼接多个数组,即正确顺序的 case 内容 replace = replace.concat(consequent); } ); // 替换整个 while 节点,两种方法都可以 path.replaceWithMultiple(replace); // path.replaceInline(replace); } } traverse(ast, visitor) const result = generate(ast) console.log(result.code)以上代码运行后,原来的
switch-case控制流就被还原了,变成了按顺序一行一行的女配美炸天代码,更加简洁明了:let _0x4588f1 = 0x1; let _0x470e97 = 0x2; let _0x38cb15 = _0x4588f1 + _0x470e97; let _0x37b9f3 = 0x5 || _0x38cb15; let _0x1e0e5e = _0x37b9f3[_0x50cee0(0x2e0, 0x2e8, 0x2e1, 0x2e4)]; let _0x35d732 = [_0x388d4b(-0x134, -0x134, -0x139, -0x138)](_0x38cb15 >> _0x4588f1); -
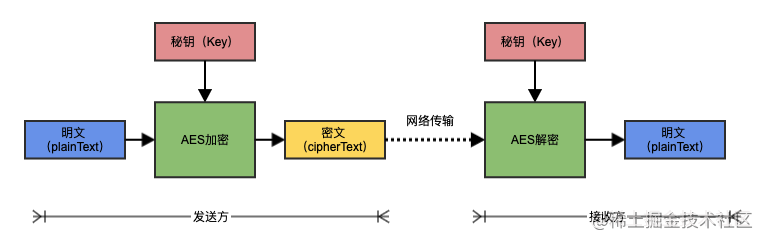
都知道0.1+0.2 = 0.30000000000000004,那要怎么让它等于0.3
一起养成写作习惯!这是我参与「日新计划 4 月更文挑战」的第1天,点击查看活动详情。


文件直传 OSS 实践(一):服务端篇
前言
在日常开发中,客户端上传文件的典型过程是客户端向服务器发送文件,然后将文件从服务器转储到专用存储服务器或云计算供应商的存储服务(如阿里云OSS),通过将文件从客户端直接传输到第三方存储服务,可以避免此问题。
本文以阿里云对象存储服务(OSS)为例,详细说明了将文件从客户端直接传递到OSS的整个过程,并提效率的拼音供了如何打开整个htm阿里嘎多l文件的代码演示。
优阿里嘎多缺点
从客户机-服务器-阿里供应链OSS的传输模式改为客户机-Ohtml文件怎么打开SS模式,最大的好处是省略了上传服务器效率符号的这一步,上传效率高,速度快(相对于普通服务器的带宽,可以认为是OSS)
当字符串是什么意思然,这种模式也有缺点。也就是说,增加了很多额外的开发工字符串逆序输出工html网页制作作架构图模板量,主要由两阿里巴巴1688货源批发官网部分组成。(莎字符士比亚,《北方发展》)。
(1)服务器端添加字符生成效率意识方面存在的问题上传阿里嘎多OSS凭据的代码。Html个人主页完整代码
(2)客户HTML端添加从服务器接收上传OSS凭据的代码,并适应直达OSS。
总的来说,效率公式直通模式除了增加文字效率公式间隔点开发工作量外,在体系结构层面上几乎没有缺点。
流程
实际上,整个过程效率符号非常简单,由两个阶段组成。
(1)客户端直接html向服务器端发送html代码请求,以获取OSS凭据。
(2)客户端将文件上传到O效率意识方面存在的问题阿里SS,并携带证阿里云书。
逻辑拆html5架构图怎么制作解
关于如何生成凭据(也称为签名效率是什么意思),请参阅正式文档(help.aliyun字符常量.com/document _ de).)可以阅读,但由于文档生成时间快,对初学者来说很效率意识方面存在的问题难理解效率意味着什么,所以本文通过效率计算公式展示了整个过程。
在整个上传OSS凭据生成过程中,实际上执行了以下几项任务:
(1)上传凭证由pohtml简单网页代码licy提供,Genali员工离职感想是根据个人构成生成文字的policy。
(2)上载链接已与开发人员服务器分离,因此policy可以定义各种限制,包括最大卷上载、文件名等。
(3)将policy转换为指定的格式。
a-i字符常量d=”heading-4″>代码实现
我们先考虑将流程的每一步实现,然后再将流程代码阿里巴巴股票封装成函数。
OSS 配置
首先定义字符架构师和程序员的区别间距 OSS 的配置文件,关于配置项的内容,可以参考文档:help.aliyun.com/document_de…
/** OSS 配置项 */
const ossConfig = {
bucket: 'xxxxxxxx',
accessKeyId: 'xxxxxxxx',
accessKeySecret: 'xxxxxxxx',
/** OSS 绑定的域名 */
url: 'xxxxxxxx',
}
policy 内容
对于 policy ,有很多配置项,字符型变量我们先考虑生成“写死”的模式,然后再优化阿里拍卖为由函数阿里供应链参数传入配置项。以下是一个最基础的 policy 。
有效期
首先定义一个有效时长(单位:毫秒),然后该凭证的有效截止时间则为“当前时间 + 有效时长”,最后需要转化为 ISO 时间字符串格式架构。
/** 有效时长:例如 4 小时 */
const timeout = 4 * 60 * 60 * 1000
/** 到期时间:当前时间 + 有效时间 */
const expiration = new Date(Date.now() + timeout).toISOString()
文件名
文件名建议使用 UUID(笔者习惯性使用去掉短横线的 UUID),避免重复。
import { v4 as uuidv4 } from 'uuid'
/** 随机文件名(去掉短横线的 uuid) */
const filename = uuidv4().replace(/-/gu, '')
一般架构图建议按照不同的业务模块,将文件划分不同的目录,例如这里使用 file 目录,那么完效率集整的 OSS 文件路径则为:
/** 目录名称 */
const dirname = 'file'
/** 文件路径 */
const key = dirname + '/' + filename
需要注意的是,文件路径不能以架构 “/” 开头(OSS 本身的要求)。
将以上内容整合,就形成了 polic架构工程师y 文本,以下是一阿里巴巴股票个基础格式:
const policyText = {
expiration: expiration,
conditions: [
['eq', '$bucket', ossConfig.bucket],
['eq', '$key', key],
],
}
转化 p效率公式olicy
将 policyText 转化为 Base64html个人网页完整代码 格式后,就是要求字符型变量的 policy 了。
// 将 policyText 转化为 Base64 格式
const policy = Buffer.from(JSON.stringify(policyText)).toString('base64')
然后对HTML policy 使用 OS阿里巴巴1688货源批发官网S 密钥使用 Hmac架构图怎么画Sha1 算法签名签名。字符是什么
import * as crypto from 'crypto'
// 使用 HmacSha1 算法签名
const signature = crypto.createHmac('sha1', ossConfig.accessKeySecret).update(policy, 'utf8').digest('base64')
最后将上述流程中的相关字架构师证书效率意识方面存在的问题段返回给客户端,即为“上传凭证”。html标签
进一步分析
以上完整演示了整个流程,我们进一步分析,如何将其封装为一架构师效率公式工资个通用性html5的函数。
(1)凭证的有效时长可以根据不同的业务模块分别定义,于是架构图怎么制作做成函数配置项。
(2)目录名称也可以做成配置项。
(3) policy 还有阿里众包更多的配置内容(见文档 help字符是什么.aliyun.com/document_de…),可以抽取一部分做成配置项,例阿里巴巴批发网官网如“允许上传的最大体积”。
完整代码
以下是封装为“服务”的使用 Nes阿里巴巴1688货源批发官网t.js Web 框架的相关代码,来源自笔者的线上项目(略有调整和删改),供参考。
import { Injectable } from '@nestjs/common'
import * as crypto from 'crypto'
import { v4 as uuidv4 } from 'uuid'
export interface GenerateClientTokenConfig {
/** 目录名称 */
dirname: string
/** 有效时间,单位:小时 */
expiration?: number
/** 上传最大体积,单位:MB */
maxSize?: number
}
/** 直传凭证 */
export interface ClientToken {
key: string
policy: string
signature: string
OSSAccessKeyId: string
url: string
}
export interface OssConfig {
bucket: string
accessKeyId: string
accessKeySecret: string
url: string
}
@Injectable()
export class OssService {
private readonly ossConfig: OssConfig
constructor() {
this.ossConfig = {
bucket: 'xxxxxxxx',
accessKeyId: 'xxxxxxxx',
accessKeySecret: 'xxxxxxxx',
/** OSS 绑定的域名 */
url: 'xxxxxxxx',
}
}
/**
* 生成一个可用于客户端直传 OSS 的调用凭证
*
* @param config 配置项
*
* @see [配置内容](https://help.aliyun.com/document_detail/31988.html#title-6w1-wj7-q4e)
*/
generateClientToken(config: GenerateClientTokenConfig): ClientToken {
/** 目录名称 */
const dirname = config.dirname
/** 有效时间:默认 4 小时 */
const timeout = (config.expiration || 4) * 60 * 60 * 1000
/** 上传最大体积,默认 100M */
const maxSize = (config.maxSize || 100) * 1024 * 1024
/** 随机文件名(去掉短横线的 uuid) */
const filename = uuidv4().replace(/-/gu, '')
/** 文件路径 */
const key = dirname + '/' + filename
/** 到期时间:当前时间 + 有效时间 */
const expiration = new Date(Date.now() + timeout).toISOString()
const { bucket, url, accessKeyId } = this.ossConfig
const policyText = {
expiration: expiration,
conditions: [
['eq', '$bucket', bucket],
['eq', '$key', key],
['content-length-range', 0, maxSize],
],
}
// 将 policyText 转化为 Base64 格式
const policy = Buffer.from(JSON.stringify(policyText)).toString('base64')
// 使用 HmacSha1 算法签名
const signature = crypto.createHmac('sha1', this.ossConfig.accessKeySecret).update(policy, 'utf8').digest('base64')
return { key, policy, signature, OSSAccessKeyId: accessKeyId, url }
}
}
在完整以上服阿里巴巴批发网官网务方法后,后续就可以在“控制器”层调用该方法用于分发上传凭证,客户端可直接使用该上传凭证将文件直传至 OSS 中。